지능 로봇을 활용한 물류 시스템에서 시각처리 기술 기반 정확한 창고 물품 인식 기술
작성자 : 백승렬 울산과학기술원 인공지능대학원 교수 2022.11.01 게시서론
디지털 물류 분야에서 로봇의 적용을 탐구하고 창고 (warehouse) 분야에서 효율적인 운영, 에너지 절약을 달성하기 위해 시각처리 기술을 활용한 물품 분류 연구를 수행한 논문이 MDPI sustainablity 지 ("Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations") 에 2022년 6월 출판되었다. 본 고에서는 해당 기술의 수준을 필자의 시각을 빌려 짚어보고자 한다.
소비자의 요구는 점차 다양화되어 가고 또한 개인화되는 방향으로 발전하고 있어 주문의 정확성과 신속성은 고객 만족도를 높이는 중요한 요소가 되고 있다. 물류 보관 시스템의 운영을 보다 효율적이고 유연하게 만들고 물류 환경에서 물품을 잡고 옮기는 과정의 효율성을 향상시키기 위해 많은 기업에서 지능형 피킹 로봇 (intelligent picking robot)을 도입하기 시작했다. 창고 및 물류 분야에서 '인간을 대체하는 로봇' 붐이 일고 있으며 이러한 추세는 가속화될 전망이다.
징동 (Jingdong) 아시아 창고는 중국에서 선도적인 위치에 있다. 일반 상품의 보관 구역에서 상품이 위치한 보관 상자는 선별 장비를 통해 자동 컨베이어 벨트로 신속하게 운송된다. 선반에서 물품을 잡는 테이블까지의 과정은 완전 자동이지만 물품을 잡는 테이블에서 규칙적인 모양의 상품을 잡는 공기 흡입 로봇 팔은 아직 많은 수가 확보되지 못했다. 이러한 물품을 집는 작업은 그 복잡성과 부족한 인프라로 인해 아직 많은 수작업을 필요로 한다. 로봇 팔로 상품을 완전히 잡을 수 있고 포장 자동화가 구현된다면 그제서야 비로소 자동화 창고가 실현될 수 있을 것으로 예상된다.
창고에서 로봇이 물건을 집는 과정에서 효율적이고 정확하게 화물을 식별하는 것은 지능형 로봇 작동이 정확하게 동작하기 위한 전제조건이다. 특히나 복잡한 물류 환경에서 화물을 올바르게 식별하는 것은 쉽지 않은 기술이다. 해당 논문에서는 딥러닝 기술 중 영상 분류를 수행하는 콘볼루션 뉴럴 네트워크 (CNN: convolutional neural network)을 활용하여 임의의 형상을 하고 있는 물체에 대한 인식 모델을 구축한다. 인식 모델은 실시간으로 상품의 식별과 분류를 수행하고, 모양, 크기, 표면 재질, 무게와 같은 검색 기반의 다양한 특성과 결합하여 다양한 유형의 상품에 대해서 물품을 잡는 그랩(grab) 솔루션을 제공한다.
로봇 팔의 종류와 작동 방식
물류 및 창고 분야에서 시각 인식 기술을 적용하면 신속하고 정확하게 상품을 식별하고 분류할 수 있으며 물류 분야의 효율성을 향상시킬 수 있다. 구동 구조와 전원에 따라 로봇 팔은 주로 유압 구동, 공압 구동, 전기 구동 및 기계 구동으로 구분된다. 유압식과 전기식은 구조적인 특징이 복잡한 반면, 공압은 구조가 간단한 편이고, 기계식은 구조가 중간 정도의 복잡성을 가진다. 설치와 제어 면에서는 유압식과 공압식이 유연성을 많이 가지는 반면 전기식이 그 다음이고, 기계식이 가장 유연성이 떨어진다. 잡는 강도는 유압식이 가장 높으며, 공압, 전기, 기계식이 비슷하게 약한 강도를 가진다. 정확도 측면에서는 기계식과 전기식이 높은 정확도를 제공하고 유압식과 공압식은 적정한 정확도를 제공한다. 반응 빠르기는 공압식이 느린 편이고, 유압, 전기 및 기계식은 빠른 속도를 제공한다. 신뢰성은 유압식이 가장 높은 반면, 전기식이 중간 정도의 신뢰성을 가지며 공압과 기계식은 신뢰성이 낮다. 가격 면에서는 유압식이 가장 비싸고, 공압, 전기 및 기계식은 저렴한 편이다. 로봇팔의 작동 방식은 네가지로 요약할 수 있는데, 후크 브래킷 방식 (Hook bracket), 스프링 로드 (Spring loaded) 방식, 잡는 (Grab-type) 방식, 공기 흡입 (Air suction) 방식이다. 1) 후크 브래킷 방식은 로봇이 물품을 잡기 위해 잡기, 걸기 등의 동작을 활용하는 방식이다. 구조가 간단한 편이고, 구동 요구사항이 낮으며 수평 또는 수직으로 이송 작업을 수행할 수 있다. 대형 기계 및 장비의 구동에 적합한 방식이다. 2) 스크링 로드 방식은 잡는 동작이 주로 제품을 조이는 스프링의 힘에 달려 있는 방식으로 주로 작고 가벼운 물품을 잡는데 활용된다. 3) 잡는 방식은 기계 손가락으로 물품을 잡는 방식이며, 대상 제품에 따라 기계식 손가락의 모양과 수를 다르게 설계해야 하는 방식이다. 산업용 로봇에서 가장 일반적으로 활용되는 방식이다. 4) 공기 흡입 방식은 가스를 압축하여 압력차이를 통해 흡착을 생성하는 방식이다. 구조가 간단한 편이고 구입하기 쉬우며 조작하기 쉽고 상품 위치 지정에 대한 요구사항이 낮아 상품 배치에 유연성이 있다. 적용 범위가 넓으며 특히 제품의 한쪽 면만 접촉할 수 있는 경우에 공기 흡입 방식이 가장 쉽게 활용될 수 있다.
물품 데이터 구축
웹 크롤러를 활용하여 중국 내 3대 국내 전자상거래 업체의 공개 웹사이트에서 사진 정보를 획득하고 이를 전처리한다. 모아진 제품들은 (그림 1)과 같이 주로 생활용품이며 세면 용품, 냉동식품, 문구류, 음료, 세탁용품, 식품, 종이제품, 잡화 등의 8개 카테고리로 분류될 수 있다. 모아진 8개의 카테고리의 물품들은 최종적으로 각각 2,537장, 5,626장, 5,635장, 1,784장, 2,407장, 6,906장, 5,425장, 3,216장의 영상들로 구성이 된다. 8개의 카테고리의 물품들은 각각 아래와 같은 특성을 가진다. 1) 첫번째 카테고리인 세면 용품들은 100-150g의 무게를 가지며, 플라스틱 실린더로 포장되어 있다. 다양한 직경으로 잡는 것이 가능해야 한다. 2) 두번째 카테고리인 냉동제품들은 200-1000g의 무게를 가지며 일부는 부드러운 형태로 되어 있다. 유연한 손동작으로 잡는 것이 가능해야 한다. 3) 세번째 카테고리인 문구류는 40-100g의 무게를 가지며, 플라스틱 스트립으로 포장되어 있다. 4) 네번째 카테고리인 음료는 235-2000mL의 용량을 가지며, 유리 혹은 플라스틱 병으로 구성되어 있다. 5) 다섯번째 카테고리인 세탁제품은 110-4260g정도의 무게를 가지며, 플라스틱 용기에 담겨져 있다. 6) 여섯번째 카테고리인 식품류는 16-70g의 무게를 가지며 가벼운 진공팩으로 포장되어 있다. 7) 일곱번째 카테고리인 종이제품들은 300-400g의 무게를 가지며 부서지기 쉬운 특성이 있다. 8) 여덟번째 카테고리인 잡화제품들은 모양과 무게가 다양하다는 특성이 있다. 모아진 데이터는 모델 학습 이전에 전처리가 수행되어야 한다. 먼저 잡음(noise)가 포함된 이상치 데이터는 제거하고, 주제와 무관한 데이터는 삭제하는 등 데이터 정리를 통해 30,000개의 상품을 포함하는 데이터를 정제하였다. 모델 학습 시 과적합(overfitting)을 방지하며 학습 효율을 증대하기 위해 랜덤하게 영상을 회전하는 변환을 적용하였고, 입력 사진을 32x32사이즈로 크기 변환하였다. 물체 타입에 따라 다른 방식의 잡는 방법을 택하도록 한다. 1) 첫 번째 세면 용품들은 가장자리에 일정한 호가 있고 직경이 약간 다르기 때문에 한 손으로 잡기에는 V자형 손가락을 사용하는 것이 적합하다. 구동 방법은 공압식이고, (그림 2a)와 같다. 2) 두 번째 유형의 상품은 냉동 제품으로 잡는 효과를 안정적으로 만들고, 잡는 물건의 모양과 크기에 적응할 수 있도록 유연하고 적응력 있는 양손 쥐기 방식을 채택한다 (그림 2b). 로봇팔의 손가락 모양 조합을 자유롭게 변경할 수 있고 잡는 과정이 유연하다. 3) 세 번째 상품은 문구류로 다양한 크레용, 색연필, 오일 파스텔 등 이 범주에 속하는 물체들은 크기와 무게가 다른 직육면체 형태가 많다. 따라서 (그림 2c)와 같은 조정 기능이 있는 양손 공압 클램프를 활용한다. 4) 네 번째 유형은 음료로 일부 알코올 제품 포장재가 유리인 것을 감안하여 조이는 힘이 너무 크면 병이 파손될 수 있으므로, 흡입 컵이 있는 3관절 손이 (그림 2d)와 같이 사용되었다. 5) 다섯 번째 유형은 세탁 제품으로 잡힌 물건의 무게가 보통 110g에서 4000g정도이기 때문에 큰 파지력과 높은 제어 정확도를 가진 (그림 2e)와 같은 유압 구동식 양손 그립을 채택하였다. 6) 여섯 번째 유형은 비스킷, 케이크, 음식 등의 식품으로, 쥐는 과정에서 상품이 손상되지 않도록 보호하기 위해 (그림 2f)와 같은 흡착 컵이 있는 생체 공학 소프트웨어 로봇 팔이 상품을 잡는데 활용되었다. 포장재의 표면이 매끄럽기 때문에 진공 흡착이 원활히 형성될 수 있다. 7) 일곱 번째 유형은 펌핑지, 물티슈, 화장지, 화장지, 생리대를 포함한 종이 제품이다. (그림 2g)와 같은 모터를 활용하는 양손 개폐식 합판이 활용된다. 8) 여덜 번째 유형은 수건, 동전, 물컵, 보조 배터리, 옷걸이, 구두 솔, 칫솔, 후크와 같은 다양한 잡화 물건이며 (그림 2h)에 나온 전동식 로봇 팔을 사용하였다.

그림1. 웹 크롤러를 활용해 모아진 사진 정보: (a) 세면 용품, (b) 냉동식품, (c) 문구류, (d) 음료, (e) 세탁용품, (f) 식품, (g) 종이제품, (h) 잡화
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations

그림2. 다양한 유형의 상품에 대한 다양한 방식의 잡기법 (a) 공압 드라이브가 있는 V자형 핑거 그립; (b) 양손으로 유연한 적응형 잡기; (c) 조정 가능한 양손 공압 클램프; (d) 흡입 컵이 있는 3관절 손; (e) 유압 구동식 양손 그립; (f) 흡입 컵이 있는 생체 공학 소프트웨어 로봇 팔; (g) 개폐식 합판; (h) I-limb 로봇 팔
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations
콘볼루션 뉴럴네트워크 (CNN: convolutional neural network) 를 활용한 인식 모델 구축
(그림 3)과 같은 콘볼루션 뉴럴 네트워크 (CNN: convolutional neural network) 구조를 활용하여 물품 분류를 수행하고 그에 따른 잡기 방법을 선택하도록 하였다. 이중 컨볼루션 계층과 이중 풀링 계층의 신경망 구조를 채택하고, 영상을 입력으로 하여 컨볼루션 (convolution) 및 풀링 (pooling)된 결과를 완전 연결 신경망 (fully connected neural network)를 통해 최종적으로 영상 분류 및 인식을 수행한다. 첫 번째 컨볼루션 레이어 입력은 그림의 길이(32픽셀), 그림의 너비(32픽셀), 그림의 채널 수(3채널) 및 샘플 수의 네 가지 차원을 포함하는 텐서 형태의 신호이다. 첫 번째 컨볼루션 계층의 출력 채널 수는 32개, 컨볼루션 커널의 크기는 5로서, 이미지 데이터에 대해 컨볼루션 연산을 수행하는 과정에서 각 단계는 필터를 한 픽셀 단위로 이동하며 콘볼루션 연산을 수행하며, 각 채널 데이터 주위에 추가되는 2픽셀 만큼의 0을 추가하여 콘볼루션을 수행한다. 두 번째 컨볼루션 레이어의 입력 채널 수는 32개, 출력 채널 수는 32개이다. 첫번째와 두 번째 콘볼루션 레이어 사이에 풀링 (pooling) 레이어가 존재하며 이 때 영상 크기를 1/2배 줄이게 된다. 컨볼루션 뉴럴 네트워크 (convolutional neural network) 에서 전체 연결 계층 (fully connected layers)은 분류기(또는 추론기) 역할을 수행한다. 모델 설계의 전체 구조에서 완전 연결 신경망 (fully connected neural network)의 입력은 두 번째 풀링(pooling) 작업 후 컨볼루션 신경망의 출력이다. 반복된 실험을 기반으로 하나의 은닉층만 포함하는 비교적 단순한 형태의 완전 연결 신경망 (fully connected neural network) 구조가 설계되었다. 완전 연결 신경망 (fully connected neural network) 의 입력은 1차원 행렬이 되어야 하기 때문에 컨볼루션 레이어 (convolutional layer)와 완전 연결 레이어 (fully connected layer)의 2차원 출력 결과를 1차원으로 변형할 필요가 있다. 이렇게 변형된 1차원 행렬의 크기는 32*8*8이며, 또한 전체 네트워크의 마지막 출력 크기는 잡아야 하는 객체의 수인 8로 설정되어 최종 출력이 8개 객체에 대한 확률값을 의미하도록 하였다. 과적합(over fitting) 현상을 막기 위해 정규화 (regularization) 기법이 활용되었고 이를 통해 일반화 능력을 향상시켰다. 정규화 기법은 파라미터의 절대값의 제곱을 전체 손실 함수에 더해주는 방식을 활용한다. 손실 함수로는 8개의 클래스로 영상을 분류해야 하므로 영상 분류에서 흔히 사용되는 교차 엔트로피 손실 함수 (cross-entropy loss function)를 사용하였다. 교차 엔트로피 손실 함수는 네트워크가 영상 입력에 대해서 정답 레이블에 가까운 출력물을 출력하도록 학습 시킬 수 있는 손실 함수이다. 해당 손실 함수를 최소화하기 위해 확률적 경사하강법 알고리즘을 사용하였다. 지역 최적값에 도달하지 못하는 단점을 피하기 위해 확률적 경사하강법 알고리즘 대신 "일괄 처리" 데이터를 기반으로 한 배치 확률적 경사하강법을 사용했다. 이 방법은 표준 경사 하강법과 확률적 경사 하강법을 조합한 것으로 64개 또는 128개의 학습 데이터를 일괄적으로 처리하는 값으로 사용하여 단일 샘플을 활용하는 것보다 더 강인한 기울기 정보를 얻을 수 있다. 따라서 배치 확률적 경사하강법은 고전적인 확률적 경사하강법보다 더 안정적으로 모델을 학습할 수 있다. 일괄 처리하는 데이터의 단위는 128로 설정했다. 학습 오차 (training error)와 검정 오차 (validation error)의 안정적인 수렴을 위해 학습률 (learning rate)을 낮게 설정하였다. (그림 4)와 같이 1,000번의 훈련을 통해 학습 과정의 초기(200번 이전)에 학습 오차와 검정 오차가 급격히 감소함을 알 수 있었고, 검정 오차의 감소 속도도 1,000회보다 약간 더 빨랐다. 후기 훈련 과정에서 두 오류의 감소는 상대적으로 완만했지만 전체적인 관점에서 볼 때 둘 다 결국 더 낮은 상태에 도달할 수 있었다. 또한 학습 과정 후반부에서는 검정 오차가 학습 오차보다 약간 높았으나 검정 오차는 상향 추세를 보이지 않아 모델의 과적합이 허용 가능한 범위 내에 있음을 확인할 수 있었고, 모델 학습 결과는 효과적이었다. (그림 5)와 같이 학습 정확도와 테스트 정확도는 모델 훈련 과정에서 꾸준히 증가하는 모습을 보였으며, 둘 다 초기(100라운드 이전)에 급속하게 향상되는 것을 볼 수 있었다. 지속적인 학습 과정에서 테스트 세트 데이터의 분류 정확도는 학습 세트 데이터보다 약간 낮았지만 전반적으로 여전히 잘 수행되었다. 모델의 학습 결과를 적용하여 이미지 분류가 비교적 정확했으며, 로봇 팔이 정확한 방법을 선택하여 물건을 움직일 수 있도록 목표물과 잡는 방법을 구현하였다. 약한 조명과 흐린 이미지와 같은 특수 조건에서 시스템의 성능을 검증하기 위해 단일 채널 이미지와 다른 커버율 (covered ratio)을 선택하여 이러한 상황을 시뮬레이션하고 교육 및 테스트를 수행했다. 3개의 채널을 가지는 컬러 영상은 더 많은 차원에서 더 많은 정보를 제공할 수 있으며 학습 결과는 단일 채널 영상을 활용할 때보다 훨씬 좋다. 단일 채널을 가지는 영상 데이터를 읽는 것보다 3개 채널을 가지는 영상 데이터를 읽는 데 시간이 조금 더 걸리지만, 본 연구에서 사용된 콘볼루션 뉴럴 네트워크는 기본적으로 컨볼루션 연산을 통해 단일 채널을 가지는 영상의 학습 및 인식 속도와 3개 채널을 가지는 영상의 학습 및 인식 속도를 동일하게 만든다. (그림 6)에서 보는 바와 같이 채널 갯수에 따른 학습 오류는 테스트 오류보다 약간 낮고 훈련 정확도는 테스트 정확도보다 약간 높아 약간의 과적합 현상이 있음을 나타낸다. 그러나 훈련 라운드가 증가함에 따라 테스트 오류는 낮은 수준으로 유지되고 테스트 정확도는 높은 수준으로 유지되며 지속적인 개선 추세가 있으며 과적합 현상도 허용 범위 내에 있다고 판단된다. 커버율 (covered ratio) 이 증가함에 따라 학습 정확도와 테스트 정확도는 약간 감소하였지만, 학습 정확도와 테스트 정확도의 감소 범위는 커버율의 증가된 범위보다 훨씬 낮았다. 특히 3개 채널을 가지는 영상 데이터 세트에서 커버율이 10%에 도달하면 인식 정확도가 여전히 83%를 초과한다. 이는 본 연구에서 선택한 콘볼루션 뉴럴 네트워크 모델이 복잡하고 변화무쌍한 데이터 환경에 적응할 수 있고 실제 적용 요구 사항을 충족할 수 있음을 시사한다. 위의 결과 분석을 통해 본 논문에서 설명하는 알고리즘은 물체의 시각적 영상이 깨끗하고 막힘이 없는지 또는 영상이 부분적으로 가려지는지 여부에 관계없이 매우 정확한 인식률을 달성할 수 있음을 알 수 있다. 이것은 또한 우리가 설계한 알고리즘은 적응력이 강하고 다양한 지능적 쥐기 환경에 대처할 수 있으며 물체 인식 및 조작기 쥐기 유형을 일치시키는 작업을 성공적으로 완료할 수 있음을 보여준다.
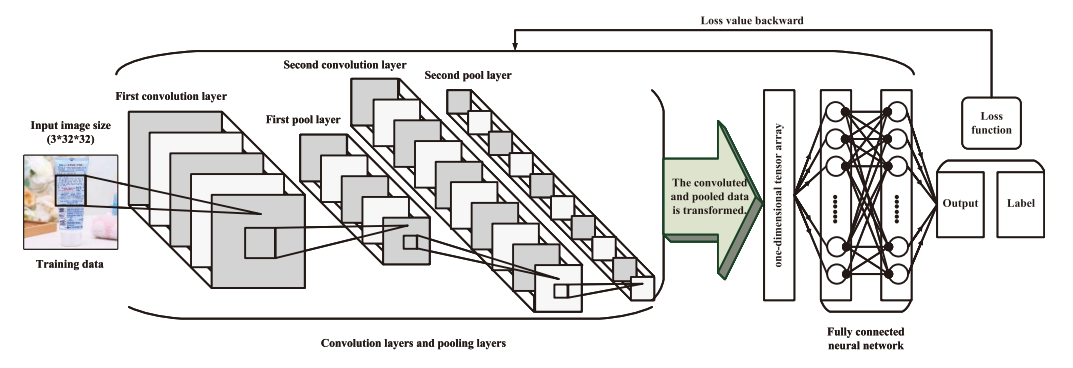
그림3. 콘볼루션 뉴럴 네트워크 구조 모식도
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations
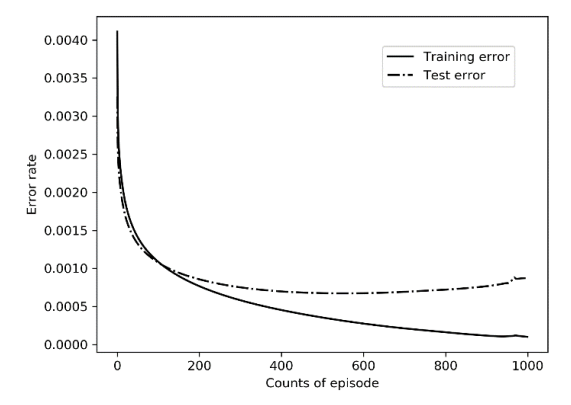
그림4. 학습 및 검정 오차
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations
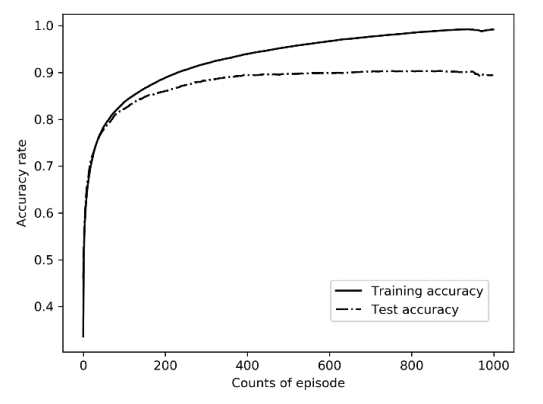
그림5. 학습 정확도와 테스트 정확도
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations
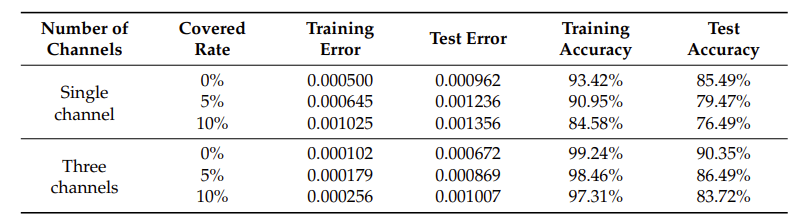
그림6. 다양한 환경에서의 학습 및 테스팅 오차 및 정확도
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations
결론
본 연구의 과학적 참신함은 물류, 창고 분야에서 지능형 로봇의 적용에 있다. 심층 신경망의 일종인 콜볼루션 뉴럴 네트워크를 적용한 시각적 인식 메카니즘을 통해 조작자가 파악한 객체의 분류를 구현하였다. 이를 창고에서 물건을 잡는 과정에 적용하여 지능형 공급망 및 디지털 물류로 확장하여 창고 로봇의 지속가능한 개발 및 효율성 향상을 위한 연구 관점을 제공한다. 본 논문에서 설명하는 방법에는 여전히 몇 가지 제한 사항이 있다. 예를 들어, 현재까지 시각적 인식의 대상은 정적인 그림으로 되어 있다. 비디오 스트림(stream) 정보 또는 3D 포인트 클라우드 (point cloud) 정보 등을 입력으로 제공할 수 있다면 응용 공간을 더욱 확장할 수 있을 것으로 예상된다. 이후 연구는 또한 조작자와 시각 인식 결과 사이의 관계를 결합해야 할 것이다. 물체에 대한 그림을 기반으로 한 잡는 동작의 유형 일치에서부터 특정 물품을 잡는 동작의 정확한 설계에 이르기까지 더 높은 수준의 지능형 물류 및 공급망 운영을 달성하고 촉진해야 할 것이다.
본 사이트(LoTIS. www.lotis.or.kr)의 콘텐츠는 무단 복제, 전송, 배포 기타 저작권법에 위반되는 방법으로 사용할 경우 저작권법 제 136조에 따라 5년 이하의 징역 또는 5천만원 이하의 벌금에 처해질 수 있습니다.
| 핵심단어 | |
| 자료출처 | Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations (2022.06.26) |
| 첨부파일 |
| 집필진 | ||