딥러닝 기반의 픽셀 레벨 (pixel-level)의 선박 탐지 기술
작성자 : 백승렬 울산과학기술원 인공지능대학원 교수 2022.12.21 게시서론
해양 안전 및 보안 분야의 연구는 해양 기반 시설의 상태를 평가하기 위한 혁신적인 시스템 개발, 테스트 및 검증에 중점을 두고 있다. 기반 시설의 보호 상태를 실시간으로 판단하고 대형사고, 자연재해 등의 위험 상황에 대응하기 위한 조치를 수행하기 위해 해양 상황 인식 시스템 개발은 중요하다. 이런 트렌드에 발맞추어, 영상으로부터 배를 검출하고, 배에 대한 픽셀 레벨의 출력을 얻는 연구가 최근 Sensors 2022 [1] 와 IEEE Trans. on Geoscience and Remote Sensing 2022 [2] 지에 출판되었다. 그림1(a)은 [1]에서 제안된 컬러 영상 기반의 픽셀 레벨의 선박 탐지 알고리즘의 예시 결과들을 나타내며 그림1(b)는 [2]에서 제안된 SAR 영상 기반의 픽셀 레벨의 선박 탐지 알고리즘의 예시 결과를 나타낸다. 그림 1(b)의 맨 왼쪽은 입력 SAR 영상이며, 가운데는 정답, 오른쪽은 제안된 알고리즘의 출력물을 나타낸다. 본문을 통해 이 기술의 수준을 알아보고 나아가야 할 방향을 필자의 시각을 빌려 소개하고자 한다.

그림1. 그림1 픽셀 레벨 선박 탐지 알고리즘 예시
[1] Ship Segmentation and Georeferencing from Static Oblique View Images, Sensors 2022. [2] FINet: A feature interaction network for SAR ship object-level and pixel-level detection, IEEE Trans. on Geoscience and Remote Sensing 2022.
딥러닝 기반의 픽셀 레벨 인식기
딥러닝 기반 객체 인식 [3, 4, 5, 6, 7, 8]은 컴퓨터 비전 분야의 연구 주제 중 하나이며 컬러 영상 기반으로 선박을 인식하는데에도 적용이 될 수 있다. 이 분야의 최근 추세 중 하나는 박스 (box) 형태로 객체를 인식하는 알고리즘 [7, 8]에서 벗어나서 픽셀 레벨로 객체를 인식하는 알고리즘 [3, 4, 5, 6]을 개발하는 것이다. 그림 2에서는 박스 형태로 객체를 인식하는 알고리즘과 픽셀 레벨로 객체를 인식하는 알고리즘의 차이를 보여주고 있다. 물체 검출 (object detection) 알고리즘에서는 박스 형태로 객체를 인식하며, 이 박스에는 해당 물체에 포함되지 않는 픽셀도 포함한다는 점에서 한계점이 있다. 예를들어, 파란색 박스에는 개(dog)가 주요 물체로 포함되어 있지만, 개에 해당하지 않는 배경 픽셀도 이 파란색 박스에 포함이 된다. 반면, 오른쪽 객체 분할 (instance segmentation) 알고리즘에서는 박스 형태가 아닌 픽셀 레벨의 정확한 객체 검출이 이루어지기 때문에 주어진 영역 분할 결과에서는 픽셀들이 모두 개(dog)에 포함되도록 학습이 이루어진다. 따라서 객체 분할 알고리즘이 박스 형태의 결과물을 추정하는 물체 검출에 비해 정확도가 높다고 볼 수 있다. 기존의 선박 탐지 논문들 [9, 10]은 박스 형태로 선박들을 탐지했지만, 본 고에서 살펴볼 논문 [1, 2]들은 픽셀 레벨로 객체를 인식하는 알고리즘 [3, 4, 5, 6]에 기반하여 픽셀 레벨로 선박을 인식하는 알고리즘을 제안하고 있다.
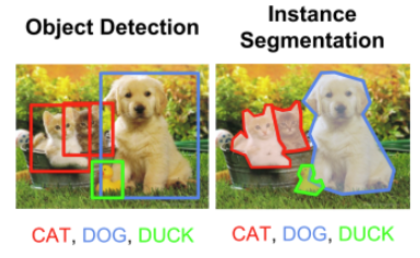
그림2. 박스(box)형태로 객체를 인식하는 물체 검출 (object detection)과 객체 분할 (instance segmentation) 알고리즘의 차이점을 보여주고 있다.
https://seeme.ai/blog/deep-learning-a-definition/
픽셀 레벨의 선박 탐지를 위한 데이터 셋
기존에 선박 탐지를 위한 데이터셋이 [9, 10] 논문 등을 통해 제안되었으나, 픽셀 레벨의 선박 탐지를 위한 딥러닝 학습을 위해서는 픽셀 레벨의 정답이 필요하나, 이전에 존재하는 데이터셋들은 그러한 픽셀 레벨 (pixel-level)의 정답이 존재하지 않는다. 또한 선박의 종류가 제한적이다. [1] 논문에서는 선박의 객체 분할 (instance segmentation)을 위해 ShipSG라고 불리우는 새로운 데이터셋을 제안하였다. 이 데이터셋에는 픽셀 레벨의 정답이 메겨져 있으며, 지리적 선박 위치에 대한 정보도 함께 가지고 있다. 데이터셋은 아래 링크에 공개되어 있다 (https://dlr.de/mi/shipsg). 이 데이터셋은 독일 브레머하펜 (Bremerhaven) 항구에서 두 대의 카메라를 사용해 수집되었다. 갑문 입구와 항구가 위치한 강에 두 대의 카메라가 위치했고, 부분적으로 겹치는 시야를 가지고 있다. 포트 유역은 카메라에서 400m 범위내에 있으며, 최대 약 1200m 떨어진 곳에서 배를 볼 수 있다. 2020년 가을 맑고 흐리고 바람이 많이 불고 비가 오는 기상 조건의 낮 시간 동안에 촬영이 이루어졌다. 조석 범위는 3m~4m사이였고 영상에 등장하는 차량과 사람은 익명으로 처리되었다. 그림 3(a)는 첫번째 카메라에서 보는 시점이고, 그림 3(b)는 두번째 카메라에서 보는 시점이다. 그림 4는 데이터셋에서 수집된 배의 종류를 보여준다. 수집된 배의 종류는 아래와 같다. (a) 화물선 (Cargo), (b) 예인선 (Tug), © 특수선1 (Special 1): 크레인선, 준설선, 어선, (d) 유조선 (Tanker), (e) 법 집행선 (Law Enforcement): 경찰 선박 및 해안 경비대 선박, (f) 여객/유람선 (Passenger/Pleasure) (g) 특수선2 (Special 2): 연구 및 조사선, 수색 및 구조선, 도선선을 가리킨다.

그림3. ShipSG 데이터셋을 수집하는데 사용된 카메라 시점
Ship Segmentation and Georeferencing from Static Oblique View Images, Sensors 2022.

그림4. 수집된 배의 종류. (a) 화물선 (Cargo), (b) 예인선 (Tug), ⓒ 특수선1 (Special 1): 크레인선, 준설선, 어선, (d) 유조선 (Tanker), (e) 법 집행선 (Law Enforcement): 경찰 선박 및 해안 경비대 선박, (f) 여객/유람선 (Passenger/Pleasure) (g) 특수선2 (Special 2): 연구 및 조사선, 수색 및 구조선, 도선선
Ship Segmentation and Georeferencing from Static Oblique View Images, Sensors 2022.
픽셀 레벨 선박 탐지 실험
컬러 영상으로부터 객체 분할 작업을 수행하기 위해 [3, 4, 5, 6]의 최신 컴퓨터 비전 알고리즘을 활용하였다. Mask RCNN [3]은 Faster RCNN [7] 알고리즘의 픽셀 레벨 검출을 위한 확장 알고리즘이며, 첫단계로서 여러개의 물체 후보 영역을 검출하고, 검출된 후보 영역에서 관심있는 물체를 인식하는 순서로 진행되는 2단계로 구성된 알고리즘이다. Detectors [4] 알고리즘은 atrous convolution이라고 하는 새로운 콘볼루션 (convolution) 연산을 제안하여 성능 향상을 가져온 방법론이며, Yolact [5] 는 1단계로 구성된 알고리즘으로 병렬적으로 후보 영역과 물체 인식을 진행함으로써 속도를 빠르게 인식하는 알고리즘이다. Centermask [6] 또한 1단계로 구성된 알고리즘이며, 실시간 성과 함께 Yolact [5]보다 정확한 성능을 제공하는 것으로 알려져 있다. 알고리즘들을 평가하는 성능 지표로서는 정확도 측정을 위해 평균 정밀도 (average precision; AP)를 활용하였고, 속도는 초당 프레임 수 (frame per second; FPS) 가 활용되었다. 네가지 알고리즘을 기반으로 픽셀 레벨의 선박 탐지를 수행한 결과가 그림5에 나와 있다. 정확도 면에서는 Mask RCNN [3] 및 Detectors [4] 알고리즘이 월등한 반면, Yolact [5]와 Centermask [6] 알고리즘은 성능이 조금 떨어지지만 FPS 기준 속도 면에서 장점이 있는 것을 알 수 있다. 20 FPS가 넘으면 실시간 성으로 간주하기에 [3, 4] 알고리즘은 실시간 응용 분야에 적용이 어렵지만 성능이 강건한 응용분야에 적합하며 [5, 6] 알고리즘은 성능이 열화되지만 실시간 응용이 필요한 분야에 사용이 가능함을 볼 수 있다. 또한 Yolact [5] 알고리즘은 작은 물체에 대한 성능 (mAP_S) 지표가 다른 알고리즘에 비해 많이 좋지 않지만, 비교적 큰 물체에 대해서는 (mAP_L) [3,4] 알고리즘에 비해 성능이 나쁘지 않음을 확인할 수 있다. [3, 4, 6] 알고리즘은 전반적으로 물체의 크기와 상관없이 성능이 고른 편이다.
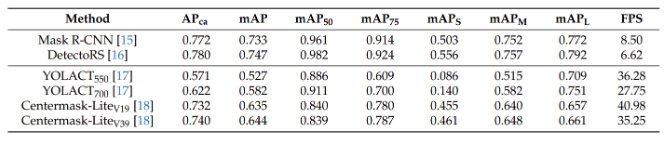
그림5. 4가지 알고리즘에 대한 평가 결과
Ship Segmentation and Georeferencing from Static Oblique View Images, Sensors 2022.
Synthetic Aperture Radar (SAR) 영상을 활용한 픽셀 레벨 선박 탐지 기술
앞서 살펴본 컬러 영상 기반의 선박 탐지 기술 [1]에 비하여 SAR 센서는 언제 어떤 날씨 조건에서도 공유 가능한 공간 정보를 제공할 수 있으므로, 군사 및 민간 선박 탐지에서 중요한 역할을 담당한다. [2] 논문에서는 SAR 영상을 활용하여 픽셀 레벨의 선박 탐지 기술을 개발하였다. 또한 [1] 논문에서 소개한 Mask RCNN [3] 기반, Yolact [5] 기반의 픽셀 레벨 탐지 기술보다 SAR 영상에서 동작을 잘하는 FINet이라는 새로운 알고리즘을 제안하였다. FINet은 물체 레벨 (object-level)과 픽셀 레벨 (pixel-level)의 두 정보를 함께 사용하는 다중 작업 (multi-task) 학습과 다양한 스케일의 물체를 잡도록 여러 스케일의 특징 벡터 (feature vector)를 추출해 한꺼번에 활용하는 다중 스케일 (multi-scale) 특징 추출기를 활용하여 성능을 향상 시켰다. 다중 작업 학습은 네트워크가 학습 시 보지 못한 데이터에 대해 잘 동작하도록 만드는 일반화 기법 중의 하나이다. 본 연구에서는 물체 레벨 (object-level)과 픽셀 레벨 (pixel-level)의 두 정보를 함께 활용하여 네트워크를 학습하였으며 이러한 두 가지 정보를 모두 사용했다는 점에서 다중 작업 학습으로 불리운다. 물체 레벨 정보는 앞서 박스(box) 형태로 물체를 검출하는 알고리즘에서 활용되던 박스 정보를 활용하여 학습하는 방식을 말하며, 픽셀 레벨 정보는 픽셀 레벨의 물체에 대한 정답을 가리킨다. 이 두 가지 정보를 모두 활용하여 네트워크를 학습함으로써 보다 정확한 성능을 얻을 수 있었다. 그림 6은 이 두가지 정보를 섞는 특징 상호작용 모듈 (Feature interaction module; FIM)의 구조를 나타내고 있다. 물체 레벨 정보 (O)와 픽셀 레벨 정보 (P)가 서로 이어지며 (concatenated), 혼합되어 새로운 물체 레벨 정보 (O)와 픽셀 레벨 정보 (P)가 얻어지게끔 네트워크 구조가 구성되어 있다. FIM 모듈을 통해 물체와 픽셀 레벨의 상호작용이 고려되었다면, 각각의 레벨에서의 최종 특징을 추출하기 위해 특징 유도 모듈 (Feature guidance module; FGM)이 이용된다. 픽셀 레벨과 물체 레벨의 상호작용을 다시 한번 고려하여 각 레벨에서의 최종 특징 벡터를 추출한다.

그림6. Feature interaction module (FIM) 구조의 모식도
FINet: A feature interaction network for SAR ship object-level and pixel-level detection, IEEE Trans. on Geoscience and Remote Sensing 2022.
SAR 영상을 활용한 픽셀 레벨 선박 탐지 기술의 실험
실험은 기존에 존재하는 HRSID와 SSDD라는 SAR영상을 기반으로 하는 데이터셋으로 진행되었다. 그중 HRSID 데이터셋은 5604장의 SAR영상을 가지고 있으며, 총 16951개의 배를 포함하고 있는 데이터셋이다. 영상 사이즈는 800x800이며 해상도는 0.5-3m정도이다. 물체에 대한 박스 정보와 함께 픽셀 레벨의 정답을 가지고 있는 데이터 셋이다. 이중 65%의 데이터가 학습용으로 활용되었고 35%의 데이터가 테스트용으로 활용되었다. 성능 메져는 정확도 (precision), 리콜 (recall), 이를 합친 F1 메져, 평균 정확도 (AP) 등이 활용되었다. 그림 7은 픽셀 레벨 알고리즘 사이의 성능 비교를 나타내고 있다. Yolact 알고리즘 [5]은 속도는 빠른 반면, 성능 면에서는 가장 좋지 않은 결과를 나타내고 있다. Mask RCNN 알고리즘 [3]은 Yolact 알고리즘에 비해서는 성능이 좋지만 제안된 FINet 알고리즘에 비해서는 성능이 좋지 못하다. 거의 모든 지표에서 제안된 FINet 알고리즘이 기존 알고리즘에 비해 성능이 월등함을 나타내고 있다. 논문 [2]에서 저자들은 제안된 FINet이 다중 작업을 수행하는 네트워크이기 때문에 그림 8에서처럼 물체레벨의 성능 또한 보고하고 있다. 우선, 1단계로 구성된 알고리즘들 (예: Yolov3, RetinaNet, Yolact) 들은 성능이 상대적으로 떨어지는 것을 볼 수 있다. Mask RCNN [3] 알고리즘이 성능면에서는 FINet 다음으로 좋은 성능을 나타내고 있다. FINet은 거의 모든 지표에서 다른 알고리즘들에 비해 좋은 성능을 나타내고 있다. 그림9 는 여러가지 픽셀 레벨 알고리즘의 결과를 보여주고 있다. 노란색 원은 해당 알고리즘이 놓치는 부분을 표기하고 있고, 빨간색 원은 잘못된 검출결과를 보여주고 있으며, 그림9의 (a)는 입력영상, (b)는 정답 영상을 보여주고 있다. 해당 영상에서 제안된 FINet이 가장 좋은 성능을 보여주고 있으며, Mask R-CNN도 좋은 결과를 보여주고 있지만, 노란색 원이 FINet보다 많아 놓치는 물체가 FINet에 비해 많은 것을 볼 수 있고, 빨간색 원 또한 FINet보다 많아서 잘못 검출하는 물체도 많은 것을 알 수 있다. FINet은 잘못 검출하는 경우와 놓치는 물체가 다른 알고리즘들에 비해 가장 적어 픽셀 레벨로 가장 잘 선박을 검출하고 있음을 보여준다.

그림7. SAR 영상을 활용한 픽셀 레벨 알고리즘의 성능 비교
FINet: A feature interaction network for SAR ship object-level and pixel-level detection, IEEE Trans. on Geoscience and Remote Sensing 2022.
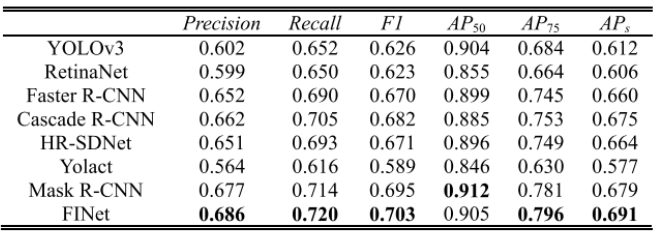
그림8. SAR 영상을 활용한 물체 레벨 알고리즘과의 성능 비교
FINet: A feature interaction network for SAR ship object-level and pixel-level detection, IEEE Trans. on Geoscience and Remote Sensing 2022.

그림9. 픽셀 레벨 결과 예시: (a) 입력 영상, (b) 정답, ⓒ VAB 결과, (d) SP-CFAR 결과, (e) Mask R-CNN 결과, (f) 제안하는 FINet 결과
FINet: A feature interaction network for SAR ship object-level and pixel-level detection, IEEE Trans. on Geoscience and Remote Sensing 2022.
본 사이트(LoTIS. www.lotis.or.kr)의 콘텐츠는 무단 복제, 전송, 배포 기타 저작권법에 위반되는 방법으로 사용할 경우 저작권법 제 136조에 따라 5년 이하의 징역 또는 5천만원 이하의 벌금에 처해질 수 있습니다.
| 집필진 | ||