선원 안전을 위한 시각AI 도입 사례
작성자 : 백승렬 울산과학기술원 인공지능대학원 교수 2023.05.03 게시서론
서론
해양 산업에서 선원들이 보여주는 안전하지 못한 행동은 선박 및 작업 사고에 중대한 영향을 미치는 요소 중 하나이다. 그림 1은 높은 고도에서 수행되는 위험한 해양 작업의 예시를 나타낸다 (그림1 왼쪽: 마스트, 그림1 가운데:외부 굴뚝, 그림1 오른쪽: 선박 크레인). 2021년 Journal of Advanced Transportation 지에서 물체 인식 알고리즘에 기반한 비디오 기반 모니터링이 안전하지 못한 행동을 실시간으로 탐지하고 선원들에게 조기 경고를 제공하는 효과적인 수단일 수 있음을 입증하였다. 해당 논문은 M.V. YuKun의 선원들이 보여준 안전하지 못한 무어링 라인 (Mooring Line; 선체와 해저에 고정된 앵커(Anchor)를 연결하는 로프, 와이어, 체인) 줄 조작 영상으로 이루어진 데이터 셋을 제시하며, 개선된 You Only Look Once (YOLO)-v4 네트워크를 기반으로 한 안전하지 못한 행동 인식 모델을 제안한다. 실험 결과는 제안된 모델이 원래의 YOLO-v4 및 YOLO-v3와 같은 다른 모델과 비교했을 때 약 35%의 인식 속도 개선과 동시에 정확도 유지를 보여준다. 또한, 계산 복잡도도 줄어드는 것으로 결과가 나온다. 제안된 모델은 실제 선박 실험에서도 성공적으로 적용되어 안전하지 못한 무어링 라인 조작 행동을 인식하는 데 효과적임을 검증했다. 실제 선박 실험 결과는 제안된 모델의 인식 정확도가 원래의 YOLO-v4와 동등하지만 처리 속도가 50% 개선되고 처리 복잡도는 약 96% 감소한다는 것을 보여주었다. 본 고에서는 시각 처리 (computer vision) 분야 기술인 물체 검출 (object detection) 기술의 발전에 대하여 살펴보고, 이를 선원 안전 응용분야에 적용한 Journal of Advanced Transportation 지의 결과를 살펴보고자 한다.

그림1. 높은 고도에서 수행되는 위험한 해양 작업 예시
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
물체 검출 기술 소개
물체 검출 (object detection)은 시각 처리 (computer vision) 분야의 한 작업으로서, 그림1과 같이 주어진 영상 및 동영상 내에서 미리 정의한 20~100여개 물체 카테고리를 사각형 박스 형태로 검출해 내는 작업을 의미한다. 시각 처리 분야에는 다양한 종류의 작업이 있지만, 그 중 2차원 영상을 가지고 수행할 수 있는 기본적인 작업에는 그림2와 같이 영상 분류 (image classification), 물체 검출 (object detection), 의미론적 영역분할 (semantic segmentation) 작업이 있다. 영상 분류 작업은, 전체 영상에 하나의 주요 물체(main object)가 있다고 가정을 한 뒤, 해당 영상 전체를 그 주요 물체에 따라 분류하는 작업이다. 영상분류는 전체 영상이 하나의 주요 물체로 구성되어 있다는 강한 가정을 활용하기에 보다 실제적인 영상 처리에 적합하지 않다. 시각처리에서는 다양한 물체로 구성된 보다 실제에 가까운 영상 처리를 위하여 물체 인식을 수행한다. 물체 인식은 영상이 다양한 물체로 구성되어 있다는 가정을 바탕으로, 영상 내 다양한 물체를 찾아내는 데 이때, 해당 물체를 꽉차게 둘러싼 네모 박스를 활용하여 물체의 위치를 검출한다. 물체의 위치 뿐 아니고 해당 박스에 해당하는 물체가 무엇인지 확률값도 추정하는 작업이다. 물체 인식 기술은 보다 실제에 가까운 영상들을 처리 가능하지만, 박스 형태로 물체를 찾는다는 점에서 한계점이 있다. 즉, 고양이를 검출하기 위해 고양이 박스를 쳤지만, 필연적으로 그 박스에는 고양이의 픽셀이 아닌 배경에 해당하는 픽셀도 존재하게 된다. 의미론적 영역분할에서는 픽셀 단위로 물체를 검출하여 이러한 한계점을 극복하고자 한다. 의미론적 영역분할은 물체인식 및 영상 분류 작업들과는 다르게 픽셀 단위로 시각처리 작업을 수행한다. 세가지 작업 중 의미론적 영역분할이 가장 진화된 형태의 시각처리 작업이기는 하지만 응용분야에 따라서는 의미론적 영역분할의 정확도와 속도가 제한되기 때문에 응용분야에 맞는 시각 처리 작업을 선택하며 실제 제품에서 영상 분류 및 물체 검출 알고리즘도 많이 활용되고 있다.

그림2. 물체 검출 (object detection) 기술 예시
https://deepbaksuvision.github.io/Modu_ObjectDetection/posts/01_00_What_is_Object_Detection.html
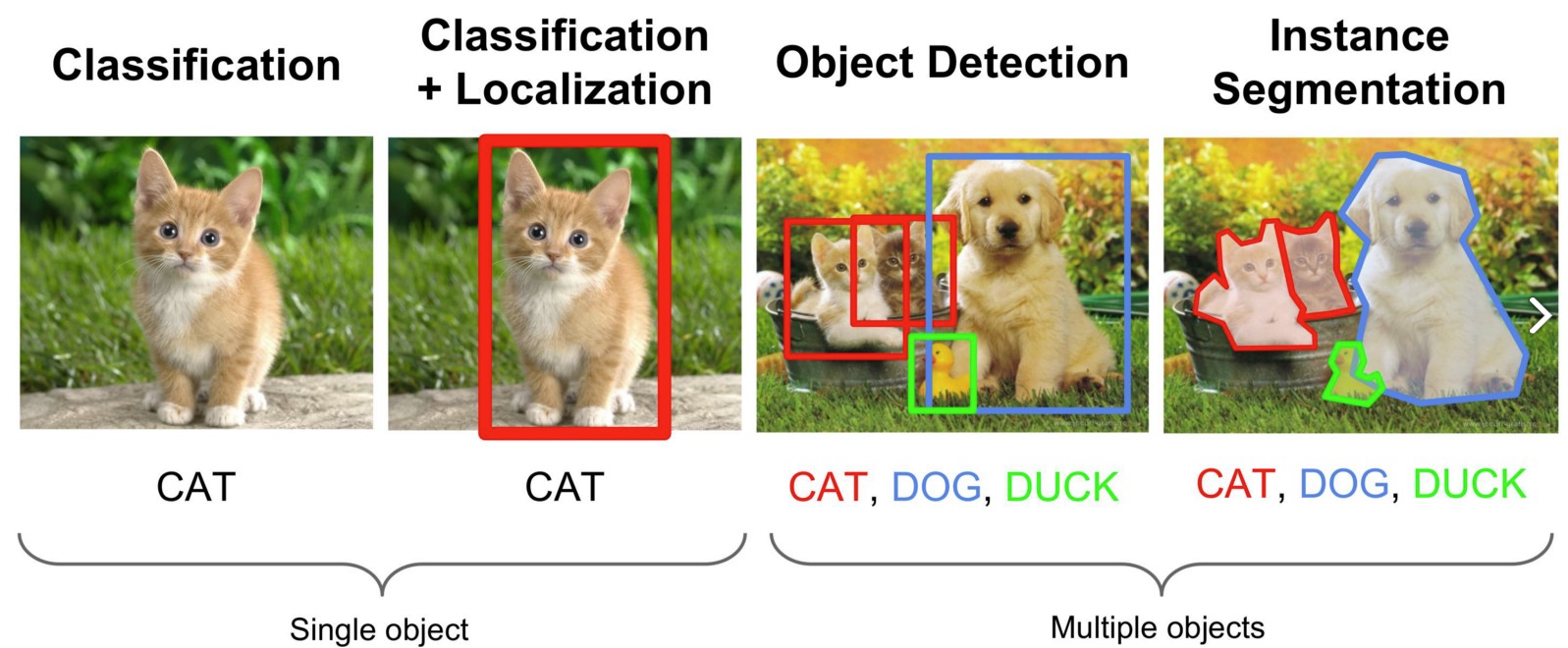
그림3. 대표적인 세가지 시각처리 작업
https://light-tree.tistory.com/75
딥러닝 (deep learning) 기술의 하나인 콘볼루션 뉴럴 네트워크 (convolutional neural network; CNN)은 영상 분류 처리 분야에서 ImageNet 데이터셋이라는 현존하는 가장 큰 영상 분류를 위한 데이터셋에서 2012년 최고 성능을 기록하며, 기존 기계학습 기반 기술의 큰 획을 그었다. 그 이후 시각처리 분야에서는 콘볼루션 뉴럴 네트워크를 다양한 시각처리 분야의 작업 (즉, 물체 검출 및 의미론적 영역분할)에도 적용하고자 하는 연구를 수행하였다. 물체 검출 분야에서 가장 먼저 등장했던 콘볼루션 뉴럴 네트워크를 활용한 알고리즘은 CVPR 2014 학회에 발표된 R-CNN (regional-CNN)이라는 이름의 알고리즘이었다. 딥러닝 알고리즘은 기존 기계학습 알고리즘들에 비하여 연산량이 많았기 때문에 하나의 콘볼루션 뉴럴 네트워크 연산을 수행하는데에도 GPU를 활용하여야 수초 내로 연산이 진행되는 등 연산량에 제약이 있다. 이러한 딥러닝 알고리즘을 물체 검출 분야에 적용하기 위해서는 여러 종류의 박스를 만든 후, 전체 영상에 이 네모 박스를 하나의 픽셀(pixel)씩 슬라이드(slide)하여 전체 영상을 다 보도록 하고, 그렇게 얻어진 네모 박스 각각에 대하여 콘볼루션 뉴럴 네트워크를 적용하는 방식으로 알고리즘을 구현할 수 있지만, 이렇게 구현할 시에는 최악의 경우 픽셀 수 만큼의 연산을 수행해야 하는 번거로움이 있고, 또한 연산량 때문에 이렇게 구현된 알고리즘은 한 장의 영상에 대하여 물체 검출을 수행하기 위해 반나절의 시간이 걸리는 비효율성이 초래될 수 있다. R-CNN 이라는 알고리즘은 이러한 비효율적인 박스 슬라이딩 기법을 활용하지 않고, 물체가 있을 만한 지역을 골라주는 선택적 검색 (selective search) 기법을 적용하여 물체가 있을만한 지역에 2000여개 박스를 만들어주는 기법을 제안하였다. 640x480 크기의 영상이 있다고 가정할 때 박스 슬라이딩 기법은 수만여개의 콘볼루션 뉴럴 네트워크를 적용해야 하는 반면 선택적 검색 기법을 적용하면 2000여번만 적용해도 되기에 효율성이 수십에서 수백배 빨라지게 되었고, 콘볼루션 뉴럴 네트워크를 물체 검출 작업에 적용한 첫 예시가 되었다. 그 이후, Fast R-CNN (CVPR 2015), Faster R-CNN (NeurIPS 2015) 기법이 등장하며, 추가적인 비효율성을 개선하여 1초 미만에 한장의 영상에서 물체 검출을 수행하는 알고리즘들이 등장하기 시작했다.
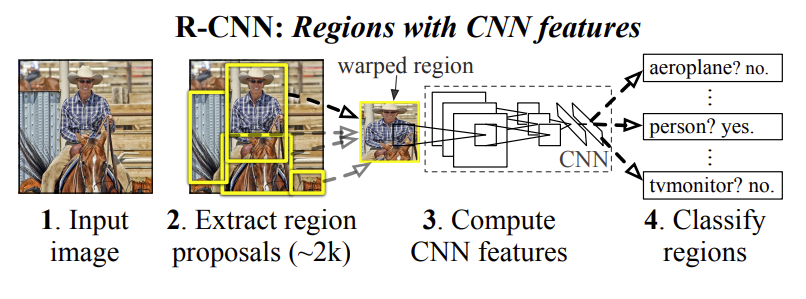
그림4. R-CNN 알고리즘 구조도 예시
Rich feature hierarchies for accurate object detection and semantic segmentation, CVPR 2014
보다 빠르고 정확하게 물체 검출을 수행하고자 하는 연구가 진행되었고, 2016년 CVPR 학회에 You only look once의 약자인 YOLO 알고리즘이 발표되었다. 박스 기반으로 영상을 추출하고 나서 추출된 박스에 콘볼루션 뉴럴 네트워크를 적용하는 R-CNN 계열의 알고리즘들에 비해 영상을 한번만 보고도 물체 검출을 수행할 수 있다고 제목을 정한 이 알고리즘은 영상 한 장에서 동시에 물체 확률값과 박스를 추정하는 방식으로 진행이 되어 알고리즘 속도가 빨랐다. 그림 4에서와 같이 한장의 영상을 7x7의 그리드(grid)로 나누고, 각각의 그리드에 대하여 2개의 물체 박스와 그리드에 존재하는 물체에 대한 확률값을 추정하도록 구성되어 있다. 이후, 물체에 대한 확률값이 높으면서 서로 겹치는 박스들은 없애주는 후처리(post-processing) 과정을 거치면 정제된 갯수의 물체 검출 결과를 얻을 수 있는 알고리즘이다. 초기 YOLO 알고리즘은 실시간성에 초점을 두었기 때문에 R-CNN 계열의 알고리즘보다 속도는 빨랐지만 성능에서는 열화되는 결과를 보여주었으나 더 깊은 네트워크를 활용하는 방식으로 YOLOv2, YOLOv3, YOLOv4 등으로 버전이 업데이트 되었고, YOLOv2에서 실시간성을 유지하면서 R-CNN 계열의 알고리즘보다 성능이 비슷하거나 월등해지는 결과를 얻어서 최근에는 실용적인 목적으로 YOLO계열의 알고리즘을 선호하고 있는 추세이다.
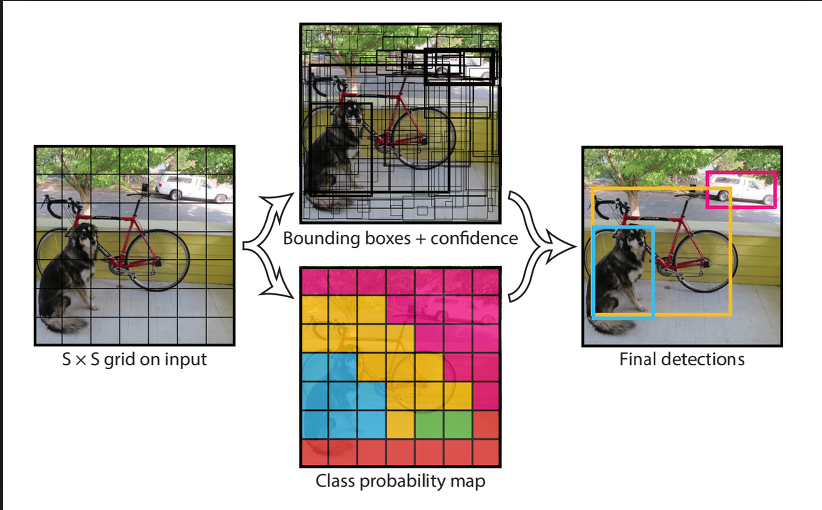
그림5. Yolo 알고리즘의 모식도
You Only Look Once: Unified, Real-Time Object Detection, CVPR 2016
물체 인식 기술을 선원 안전 시나리오에 적용한 예시
Journal of Advanced Transportation 지에 시각처리 분야 물체 검출 알고리즘의 하나인 YOLO 알고리즘을 선원 안전 시나리오에 적용한 논문이 2021년 발표되었다. 그림6은 제안된 YOLO-SD 알고리즘의 다이어그램을 보여주며, 제안된 프레임워크가 주로 아래 세 개의 네트워크로 구성된다는 것을 나타낸다. (1) 데이터 증강 네트워크: 훈련 단계에서 데이터 증강 네트워크가 설계되어 다양한 크기의 안전 로프 및 목표가 가려진 이미지의 수를 인위적으로 증가시켜 데이터셋을 보강하고, 다양한 크기의 안전 로프를 탐지하는 능력과 알고리즘의 강건성을 향상시키기 위해 사용된다. (2) 특징 추출 네트워크: YOLO v5s 프레임워크를 기반으로, 특징 피라미드 네트워크 (FPN)와 CSPDarknet53 네트워크가 사용되어 다른 크기의 이미지 특징을 추출한다. 이에 따라, 네트워크의 주요 구조는 하향식 경로, 상향식 경로 및 측면 연결을 포함하며, 세 가지 다른 해상도 및 의미 정보를 추출하고 다른 크기의 이미지 특징을 얻을 수 있다. (3) 예측 네트워크: 획득한 다중 해상도 이미지 특징을 처리하고 안전 로프를 착용하지 않은 선원과 착용한 선원을 감지하여 검출 상자와 확신도 값을 생성한다. 예측 네트워크가 안전 로프를 착용하지 않은 선원이 작업 영역에 들어오는 것을 감지하면 시스템은 이를 표시하고 감독관에게 경고음을 내어 알린다.
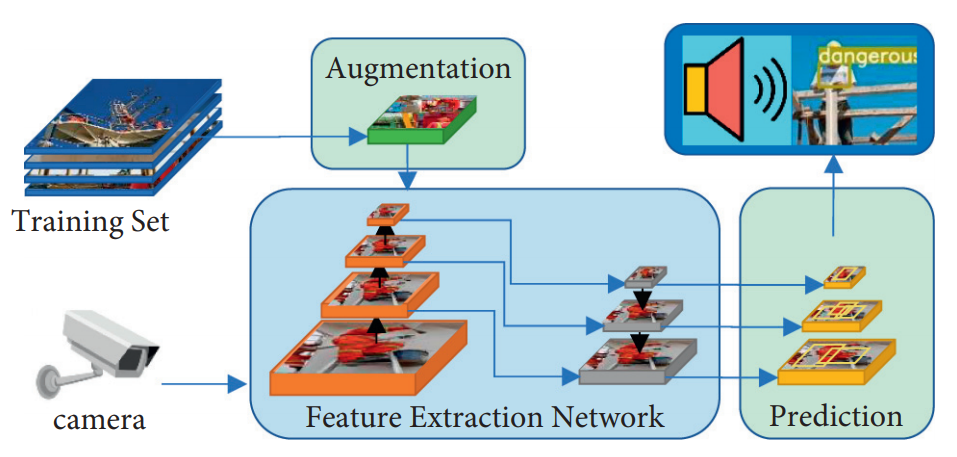
그림6. 제안된 YOLO-SD 알고리즘의 다이어그램
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
알고리즘의 훈련 및 테스트 결과는 데이터셋에 따라 달라진다. 그러나 공개된 선원 안전 로프 데이터셋은 없다. 따라서 본 연구에서는 자체적으로 선원 안전 로프 데이터셋을 생성하였다. 이를 위해 테스트 이전에 선박 내 감시 비디오와 웹 크롤러 두 가지 데이터 소스를 준비하였다. 총 3,150개의 이미지와 6,583개의 대상이 데이터셋에서 수집되었다. 선박 감시 비디오에서 이미지를 추출한 후 일부 선원을 포함한 이미지는 제외하고 라벨링되었다. 그런 다음 라벨링된 대상은 1,250개의 안전 유도구 이미지와 1,900개의 위험 사례 이미지를 포함하는 두 가지 카테고리로 나누어졌다. 알고리즘을 훈련하는 동안, 데이터셋은 16 : 4 : 5의 비율로 훈련 세트, 검증 세트 및 테스트 세트로 나누어졌다. 그림 7은 준비된 데이터셋의 일부 이미지를 보여준다.

그림7. 선원 안전 데이터셋 예시
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
제안된 알고리즘의 탐지 효과를 검증하기 위해, 표준 YOLO v5s 및 제안된 YOLO-SD 알고리즘으로부터 얻은 탐지 결과를 비교하였다. 표 1은 제안된 YOLO-SD 알고리즘이 정확도, 재현율, 평균 정확도를 개선함을 보여준다. 더 구체적으로, 탐지 속도는 7.3% 증가되었다. 제안된 알고리즘의 성능을 더 평가하기 위해, YOLO-SD, SSD 및 EfficientDet 알고리즘의 탐지 효율성을 비교하였다. 이에 따라, 테스트 결과가 표 1의 아래에 제시되었다. SSD 알고리즘이 mAP 값이 89.3%로 우수한 성능을 보이지만, SSD 알고리즘의 탐지 프레임 속도는 제안된 YOLO-SD 알고리즘의 1/3 수준에 머무른다는 것을 관찰할 수 있다. 한편, EfficientDet-d0 알고리즘이 최고의 탐지 속도인 59.30 fps를 보이며, 제안된 YOLO-SD 알고리즘의 탐지 속도는 38.31 fps이다. 그러나, YOLO-SD 알고리즘의 mAP 값은 EfficientDet-d0 알고리즘의 mAP 값보다 훨씬 높다. EfficientDet-d1 알고리즘이 EfficientDet-d0 알고리즘보다 높은 mAP 값을 보이지만, 여전히 제안된 YOLO-SD 알고리즘과는 현격한 차이가 있다. 또한, EfficientDet의 탐지 속도는 제안된 YOLO-SD 알고리즘보다 느리다는 것을 확인할 수 있다. 제안된 YOLO-SD 알고리즘이 탐지 정확도와 탐지 속도 모두를 고려하므로, 선원 안전 로프의 탐지 작업을 더욱 잘 수행할 수 있다.
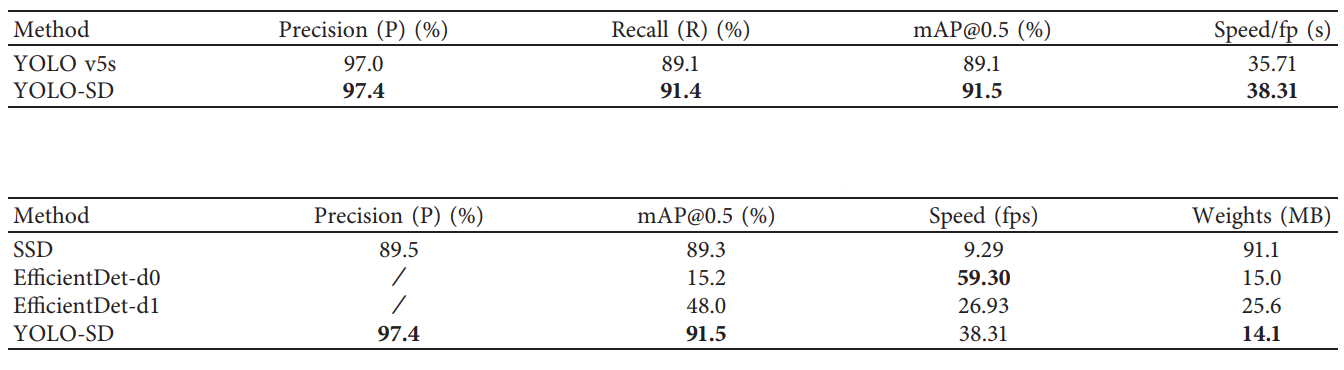
그림8. YOLO-SD 알고리즘의 성능 비교 (위) YOLOv5알고리즘과 비교, (아래) 다른 물체검출 알고리즘과의 비교
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
그림 9는 선원 안전 탐지 결과의 일부를 보여준다. 왼쪽에서 오른쪽으로, 선원의 거리와 카메라가 멀어지면서 선원의 이미지 크기가 서서히 작아진다. 각 이미지는 다른 해상도를 가진다는 것을 명시해야 한다. SSD 알고리즘이 1개의 잘못된 탐지와 2개의 오류 탐지를 보였다는 것을 확인할 수 있다. 또한, EfficientDet-d1 알고리즘이 4개의 누락 탐지를 보였다. 한편, 제안된 알고리즘은 잘못된 탐지가 단 한 개뿐이었다. 한편, 다른 이미지 해상도 및 대상 크기에서 최상의 탐지 안정성을 가지며, 좋은 탐지 효과를 보인다. 따라서, 제안된 알고리즘은 좋은 강건성을 가지고 있다고 추론할 수 있다.

그림9. 부분 테스트 결과
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
그림 9는 감시 비디오 탐지 과정의 샘플 결과를 보여준다. 제안된 YOLO-SD 알고리즘이 탐지 과정에서 좋은 결과를 보여주었음을 알 수 있다. 선원의 등 안전 로프가 때로는 철근에 부분적으로 가려진 것으로 보이지만 (그림 10 프레임 350 참조), YOLO-SD 알고리즘은 여전히 안전 로프를 감지할 수 있다.

그림10. 감시 (surveillance) 비디오 검출 결과 예시
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
알고리즘의 감지 안정성을 평가하기 위해, 낮은 조명, 야간, 비 오는 날 및 안개 낀 날과 같은 다양한 작업 조건에서 촬영된 이미지에 대한 테스트가 수행되었다. 다양한 조건에 대한 예시는 그림 11에 제시되어 있다 (그림11a: 밝기가 제한된 영상, 11b: 밤에 찍힌 영상, 11c: 비오거나 안개낀날, 11d: 해상도 낮은 영상). 영상 오염 방지 능력을 정량적으로 분석하기 위해, Perlin Noise 를 테스트 이미지에 추가했다. Perlin Noise를 적용하는 것은 특정한 텍스처 노이즈 또는 데이터 증강 세트를 생성하기 위해 널리 채택된 방법이다. 원본 이미지에 40%의 노이즈를 추가할 때, 재현율 및 mAP의 하락은 6% 미만입니다. 또한, 노이즈 커버리지가 50%와 60%로 증가할수록, 재현율 및 mAP의 하락도 각각 21% 및 35% 증가하였으나, 감지 정확도는 여전히 높은 수준을 유지하는 것을 확인할 수 있었다.

그림11. 다양한 조건하에서 테스트 수행
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
그림 12는 pyQt5 프레임워크를 기반으로한 감지 데모 소프트웨어를 보여준다. 감시 카메라를 이용하여 소프트웨어의 기능을 테스트할 수 있으며,시작 버튼을 누르면, 프로그램은 감시 비디오에서 선원을 감지하고, 감지된 선원을 표시 상자로 표시하고, 감지 정보를 로그 상자에 기록한다. 그리고 안전 로프가 없는 감지된 선원이 감시 영역에 들어올 경우, 감독자에게 알람이 울려서 알림을 준다.

그림12. 검출 데모 소프트웨어 예시
YOLO-SD: A Real-Time Crew Safety Detection and Early Warning Approach, Journal of Advanced Transportation 2021
맺음말.
본 고에서는, 시각처리 분야에서 제안된 실용적인 알고리즘의 하나인 물체 검출 알고리즘에 대하여 살펴보고, 해당 알고리즘의 선박 작업 현장에서의 적용을 다룬 논문을 리뷰하였다. 특히 선박 작업 현장에서, 안전 로프 착용을 수동 감시하는 것의 단점을 해결하기 위해 설계한 알고리즘을 살펴보았으며, 다양한 해상도와 사람 크기에서 높은 감지 정확도와 속도를 보여주는 것을 확인하였다. 수행된 실험 결과, 최신 목표 감지 알고리즘과 비교하여 YOLO-SD 알고리즘이 좋은 감지 효과를 나타내면서도 실시간으로 강건한 것을 확인하였다. 하지만, 선원 안전 로프 착용 감지 과정에서 정확도 및 속도 문제에만 초점을 맞추었으며, 인공 지능 칩이나 엣지 컴퓨팅 장치로의 알고리즘 이식에 대해 연구가 되어 있지 않다. 해당 기술에 대한 발전도 진행되면 좋을것이라 기대된다. 인공지능을 활용한 보다 많은 물류, 선박, 제조 분야에서의 활용이 기대된다.
본 사이트(LoTIS. www.lotis.or.kr)의 콘텐츠는 무단 복제, 전송, 배포 기타 저작권법에 위반되는 방법으로 사용할 경우 저작권법 제 136조에 따라 5년 이하의 징역 또는 5천만원 이하의 벌금에 처해질 수 있습니다.
| 핵심단어 | 제안 YOLO-SD 알고리즘콘볼루션 뉴럴 네트워크선원 안전 로프의미론적 영역분할YOLO-SD 알고리즘 탐지 |
| 자료출처 | |
| 첨부파일 |
| 집필진 | ||