사람에 대한 포즈와 행동을 분석하는 거대언어모델에 대한 최신 연구 동향
작성자 : 백승렬 울산과학기술원 인공지능대학원 교수 2025.05.31 게시서론
Open AI사의 ChatGPT가 도래한 이래로, 거대언어모델(large language model; LLM)은 다양한 도메인의 AI 연구에 활용되고 있다. 거대언어모델은 (1) 입력에 대해 사람이 이해할 수 있는 언어로 구체적인 설명이 가능하며, (2) 대량의 데이터로 학습이 되어, 처음 보는 새로운 입력에 대해서도 일반화가 가능하여 어느정도 설명이 가능하다는 장점이 있다. 본 고에서는 이러한 장점을 활용하여 최근 사람에 대한 행동과 3차원 포즈를 분석하는 연구에 거대언어모델을 활용한 AI 연구가 있어 이의 현 수준을 살펴보고 전망을 논의해보고자 한다.
3차원 포즈 및 행동 분석 연구
영상으로부터 사람에 대한 포즈를 3차원 메쉬 형태로 복원하여 이를 분석하는 연구는 [1] 논문에서 딥러닝 구조의 하나인 콘볼루션 뉴럴 네트워크(convolutional neural network; CNN)를 활용하여 이 네트워크가 컬러 영상을 입력으로 하여, 사람에 대한 3차원 모델인 SMPL 모델 [2]의 파라미터를 추정하도록 데이터를 모아 학습이 가능함을 보인 이후로 활발히 연구되어지고 있다. 그림1은 [1] 논문의 결과 예시로, 컬러 영상과 그의 3차원 복원된 메쉬 결과를 보여주고 있다.

그림1. [1] 논문의 결과 예시
[1] 논문
비디오에서 사람에 대한 행동을 분석하는 연구 역시 다양한 딥러닝 구조를 활용하여 활발히 연구되어지고 있는 분야이다. 또한 행동 분석에서는 딥러닝 구조를 학습하기 위한 대규모 데이터 수집이 주요 이슈였으며 [3]은 난양공대에서 수집한 대표적인 대용량 비디오 데이터에 대한 논문이다. 그림 2는 [3] 논문에서 제시된 다양한 사람의 행동에 대한 예시를 보여준다.

그림2. [3] 논문에서 수집한 데이터 예시
[3] 논문
언어모델을 활용한 3차원 포즈 및 행동 분석 기법
3차원 포즈를 자연어로 기술하려는 노력은 22년 발표된 [4] 논문에서부터 시작되었다. 이 때는 거대언어모델이 아닌 초기 생성AI 모델을 활용하여 자연어 신호로부터 3차원 메쉬를 복원하거나, 3차원 메쉬를 자연어로 기술하려는 초기 단계의 기법들이 제시되었다. 입력 영상을 3차원 메쉬 형태로 정확히 복원하고자 하는 [1]에 비하여 자연어라는 새로운 입력 및 출력을 활용하여 사용자에게 편의성을 제공할 수 있었다. 이후, [6] 논문은 Meta사의 거대언어모델인 LLaVa 모델 [5]을 활용하여 LLaVA 모델이 컬러 입력 영상 내에 있는 사람에 대한 포즈에 대한 자연어 기술을 수행할 수 있는 기법을 제안하였으며, 거대언어모델을 활용하여 [4] 논문 대비 처음 보는 포즈에 대해 기술하는 일반화 능력이 좋아지게 되었다. [7] 논문은 “걷다”, “춤추다” 등의 대략적인 표현이 아니라 “두 손을 배 앞에 놓다” 등의 보다 세밀한 행동에 대해서 기술과 포즈 생성이 가능한 PoseLLaVA 기법을 제안하였으며, [8] 논문은 그에 더하여 사람의 포즈를 보다 온전히 이해하고, 생성하며 편집할 수 있는 거대언어모델 기반 방법론을 제시하였고, 올해 6월 미국 Nashville에서 개최되는 CVPR 2025 학회에서 방법론이 발표될 예정이다. 그림 3은 [8] 논문으로 수행 가능한 작업의 예시들을 결과와 함께 보여준다.
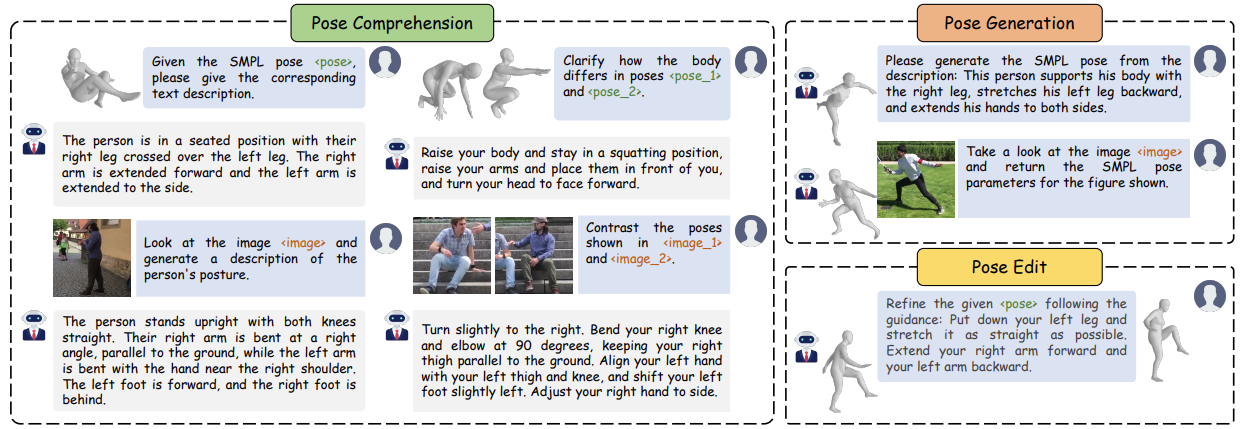
그림3. [8] 논문의 결과 예시
[8] 논문
정지된 포즈 뿐 아니라 포즈의 연속적인 움직임(motion)에 대해서도 자연어로 기술하고자 하는 노력이 [9] 논문 등을 통해 있었으며, 최근에는 [10] 논문과 같이 포즈의 연속적인 움직임으로 표현되는 사람의 행동에 대해서 거대언어모델을 통하여 기술하고자 하는 노력이 있었다. [10] 논문도 올해 6월 미국 Nashville에서 열리는 CVPR 2025 학회에서 발표될 예정이다. 해당 기법은 기존 거대언어모델이 물체와 상호작용 하는 사람의 액션 (human-object interaction)에 대한 이해가 떨어지는 부분에 특히 착안하여 대용량의 ADL-X 데이터셋을 수집하고 거대언어모델을 추가적으로 학습하여 해당 부분에 대한 자세한 기술이 가능하도록 튜닝한 기술적 기여를 가지고 있다. 그림4는 [10] 논문에서 제안한 거대언어모델인 LLAVIDAL가 출력한 사람 행동에 대한 텍스트 기술과 기존 Meta사의 언어모델인 LLaVa와 LLaMa, Open AI 사의 ChatGPT가 출력하는 텍스트 기술과의 비교를 보여주고 있으며, 사람 행동에 대한 보다 자세하고 세밀한 분석이 가능함을 보여주고 있다.

그림4. [10] 논문의 결과를 타 거대언어모델과 비교
[10] 논문
결론
본 고에서는 거대언어모델을 활용한 영상 내 사람에 대한 포즈 및 행동을 분석하는 최근 기술들에 대해 살펴보았다. 거대언어모델은 비단 언어 신호만이 아니고 최근에는 영상, 오디오, 3차원 포즈, 행동 등 멀티모달 신호들을 활용할 수 있도록 확장되고 있으며, 그 쓰임새가 더욱 실용적으로 다변화되고 있음을 알 수 있다. 해당 기술은 CCTV, 방송, 영화, 게임 등 다양한 미디어가 생산해내는 사람을 촬영한 이미지 및 비디오 영상에 대해 자연어 분석을 수행하고, 이미지 및 비디오를 편집하고 재생산해내도록 활용될 수 있다. 물류 부문에서도 다양한 활용 방법을 찾을 수 있는 기술이라 사료된다.
본 사이트(LoTIS. www.lotis.or.kr)의 콘텐츠는 무단 복제, 전송, 배포 기타 저작권법에 위반되는 방법으로 사용할 경우 저작권법 제 136조에 따라 5년 이하의 징역 또는 5천만원 이하의 벌금에 처해질 수 있습니다.
| 집필진 | ||